AGRe (Academic Gossip-based Recommender) is a website that generates recommendations for learning resources (books, on-line documentations, software tools, existing projects, public code repositories, and others), important persons (e.g., colleagues, tutors) to be contacted, good/bad points regarding the personal knowledge on the taught topics, optimal hours of study, etc.
As our society becomes ever more complex people will require more and more information. To accommodate the need for expertise in ever more diverse and specific areas online resources for learning keep multiplying. Universities are also providing open access to their courses through the internet and online only courses keep increasing in number. But the amount of resources available also makes it difficult to find the ones best suited to you and your needs.
Identifying the right materials and people to start learning can have a significant impact on what a student learns and how fast he does it. AGRe will try to make smart recommendations to the user about which books they should read, what courses they should take, who are the experts in the field and what other resources are available on the web.
To do this AGRe combines several data sources about books, universities, scientific publications and other web content. The content from several places is aggregated and filtered to better fit the user's query and information we have about them. Information such as the users location could be used to better identify which universities are nearby so courses and professors from these universities would be ranked higher in the search results. Information about the user's language preferences could be used to identify content that is easier for the user to understand etc.
To generate good recommendations exploiting all the information we have about the user and the data is important. To do this we must create user profiles, track information about what queries are made and what resources are used. We can combine this information to generate the show the most appropriate content for that specific user using a technique called Collaborative Filtering. This technique takes into account the users previously used resources and recommends learning materials that users who have used similar resources have selected but this user has not.
To allow this project to be reused and understood by machines the results will integrate information about the type of resource in each result and various properties related to it. To do this we use RDF metadata incorporated into the HTML in format called RDFa. We will also be using popular open ontologies such as schema.org to provide an easily understood structure to the data that can be combined with and incorporated into other applications that use the same ontologies.
To make interacting with our system as easy as possible we will create a bot that tries to accommodate talking using natural language. The bot will look for keywords and use natural language attributes such as dependencies to identify the topics the user is querying and then query AGRe and display the results in a way that fits the context in which it is being used. The bot will remember what the user said in the past and incorporate that into the resulting query. The bot will also aid in creating the user profiles by asking the user questions and saving the results.
For machines to be able to use AGRe we need to provide a different interface that relies less on visual elements or natural language but is still expressive enough to allow the use of all of AGRe's functionalities. For this we will provide a SPARQL endpoint. The SPARQL language allows developers to create queries that are specific to their needs by providing the query along with optional parameters that filter the data. Another advantage of SPARQL is its ability to query related objects along with specific properties.
Our high-level goals are to:
We hope AGRe will be useful in both helping learners by providing the right materials and highlighting the best content and people so that useful resources will continue to be developed and used. This objective is important now and is becoming increasingly more so as new technologies are developed and companies create new roles that demand more specialization. So we hope that AGRe will be easy to integrate with future applications so that as many people as possible get to become their best selves.
Courses are units of teaching that typically lasts one academic term, are led by one or more instructors and are usually taught at universities.
Books are written or printed work consisting of pages glued or sewn together along one side and bound in covers. eBooks are digital scans of books usually in the form of a PDF file.
Scholarly or peer-reviewed articles are written by experts in academic or professional fields.
Professors and other experts are people with a lot of knowledge about certain topics and, in the case of professors, engage in teaching others about it and conducting research on their chosen topics.
There is a lot of useful information on the Web that falls outside of the aforementioned categories.
The main server will be written in Python using the Django framework. For SPARQL and RDFa funcionality we will use RDFlib. For querying the APIs we will use the requests library and for scraping recevied data when neccesary we will use BeautifulSoup. For parsing natural language we will use spaCy and Wordnet using NLTK's interface. We will also use Surprise for its implementation of Collaborative Filtering. For the frontend we will use React to make an UI bot and website along with a SPARQL endpoint.
Since we need to integrate many external APIs and add a ML module to our search/recommender system we can say we have a complex design. We show it through the diagram below:
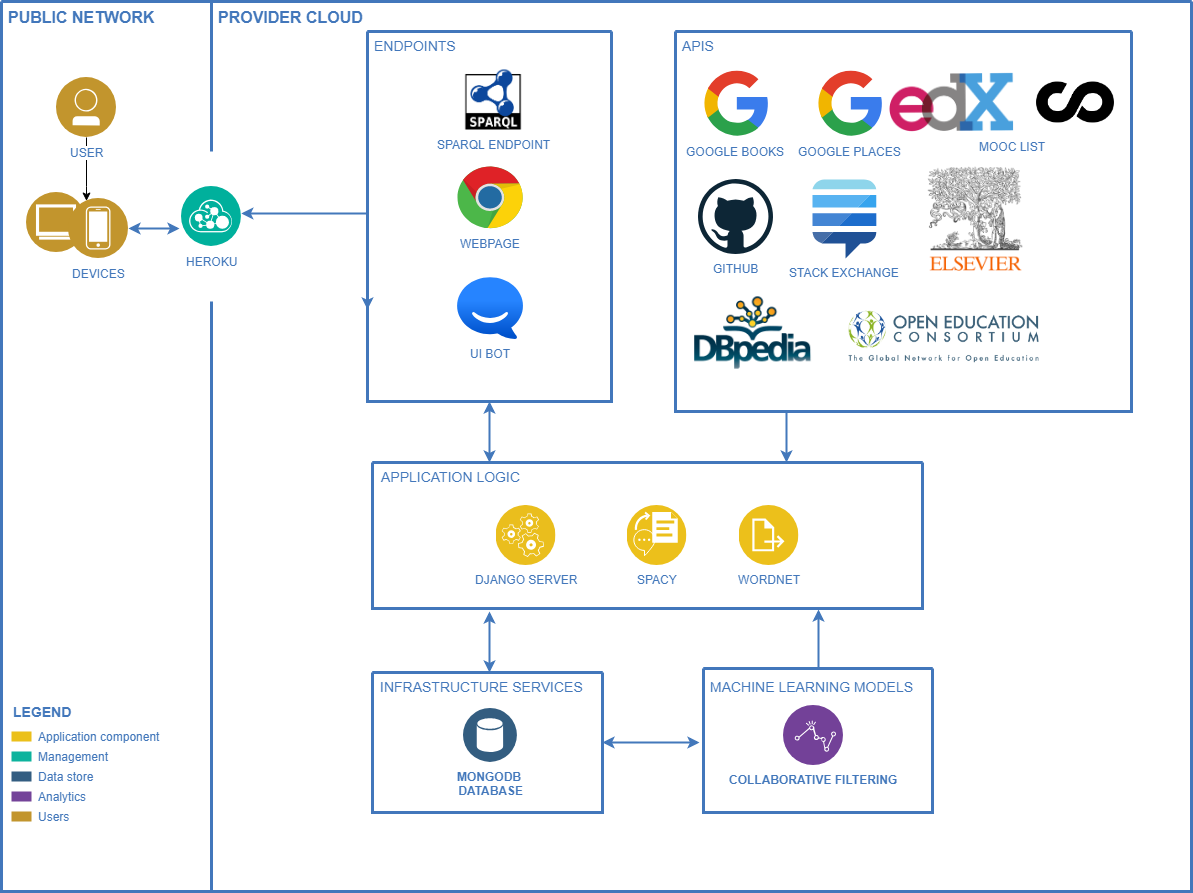
The ML module will be used to enrich the search results. At a first glance, there are a few algorithms that are useful for our application.

We will use different APIs in order to provide all kinds of resources. Below are presented some of them and the useful information we can extract.
If a new user and wants to register in AGRe, he will be needed to fill-in some questions from which our ML module will extract information regarding the Interests (and Tags) a user has. Based on those Interests on the Query Frame or Home page there will be recommended, used by teacher's rank some resources, such as Books, Articles, Online Courses etc.
The flow diagram presents the main actions and processes along a user's session.

Query Frame/Home Page

UI bot interface
